
As tradition wants, in June 2019 we attended one of the major computer vision conferences. This year the conference happened to be CVPR. Here at DVC we know how fast paced our field is and firmly believe you need to go out and learn from the best if you want to keep that pace. This is why the conference week is such an important time of the year for us.
This year CVPR was the biggest CVPR ever with over 9000 attendees.
The Computer Vision and Pattern Recognition (CVPR) conference is a well known meeting held every year around the United States.
I can safely say it is the biggest showdown of new ideas and state-of-the-art solutions in the computer vision field – and it’s also a good time to meet new and old friends and strengthen relationships within the community.

With a record 1294 papers accepted, the program for this year CVPR was very dense.
I will start by saying I could not count more than 5 (five) papers not using deep learning whatsoever in their solutions. Even if we consider the likely chances of missing a few, the number of DL-free papers is still below 1%.
Given the rarity of such papers, I want to point out one that I really liked, “On Finding Gray Pixels” from Jiri Matas’ lab.
Gray pixels have one very neat property: in a color-biased image, they capture the illumination color; and in a color-balanced image, their RGB values are all equal. If one can find the gray pixels of an image, it can leverage their biased color to restore color constancy on the whole image. By the way, our brain has a super effective color constancy algorithm, which is basically why the world always looks better from our eyes than from a picture (until now).

It’s also worth mentioning a couple of the award winning papers, as they hit some of the most interesting applications presented at the conference.
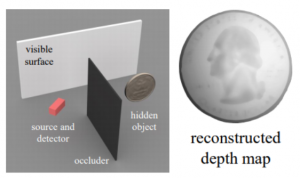
The best paper award was given to “A Theory of Fermat Paths for Non-Line-of-Sight Shape Reconstruction” from CMU.
As the word suggests, Non-Line-of-Sight Shape Reconstruction deals with the task of estimating an object shape which is not directly observable from the sensor. It’s no magic: the key insight is that any object in the scene subject to a light source reflects photons, and some of these photons will eventually reach visible objects and be reflected again towards the camera. The trick resides in controlling the light source and decoding the arrival times of these reflected photons.
Another good piece of work rewarded with a best paper honorable mention is “A Style-Based Generator Architecture for Generative Adversarial Networks” from NVIDIA.
The most striking contribution of this work resides in the ability of the generator to sample randomness at various depth and semantic-level of the generation process.
While in classical GAN architectures, only a single vector is randomly sampled to generate a new image, the proposed GAN samples three of them. In the application scenario of face generation, a random noise vector is sampled for the coarse attributes like gender, pose or hair length; one for the medium attributes like smile or hair curliness; and eventually one is sampled for finer details such as skin color. And the best part is that this coarse-to-fine distinction of details emerged naturally during learning and no supervision was provided to force it. All of this allows for i) a more controllable and intuitive interpolation space and ii) the long-sought introduction of randomness in details e.g. in the way hair are arranged on a face.

A second honorable mention goes to “Learning the Depths of Moving People by Watching Frozen People” by Bill Freeman and Google Research. The system proposed in this paper is able to predict a dense depth map from RGB images containing people “in the wild”. This has long been considered a difficult task in depth-from-RGB prediction because of the lack of datasets. To obtain sparse depth maps from videos, structure-from-motion techniques are usually employed. Nevertheless, videos with people are typically discarded because the combined motion of camera and people in the scene makes a bad case for SFM. Hence the lack of datasets. In this paper, the authors introduce a new dataset comprising a collection of YouTube videos of mannequin challenges (see https://www.youtube.com/results?search_query=maneqquin+challenge). In a mannequin challenge video, people are stationary while the scene is moving, so all geometric constraints hold and depth can be extrapolated by SFM and used to supervise a deep net.

What can we say about the remaining 1290 papers presented at CVPR?
We came home from CVPR with many good ideas to put into practice. Get in touch if you want to know more about how we apply cutting edge computer vision and deep learning solutions to real world problems.